Redis Cluster 운영 및 클라이언트 전략 정리
· 5 min read

BackEnd Software Developer
Redis Cluster 환경에서의 Topology 변화, 클라이언트 동작 방식, 그리고 Read 전략에 대한 핵심 내용을 정리합니다. 실무 및 면접에서 바로 활용 가능한 내용으로 구성하였습니다.
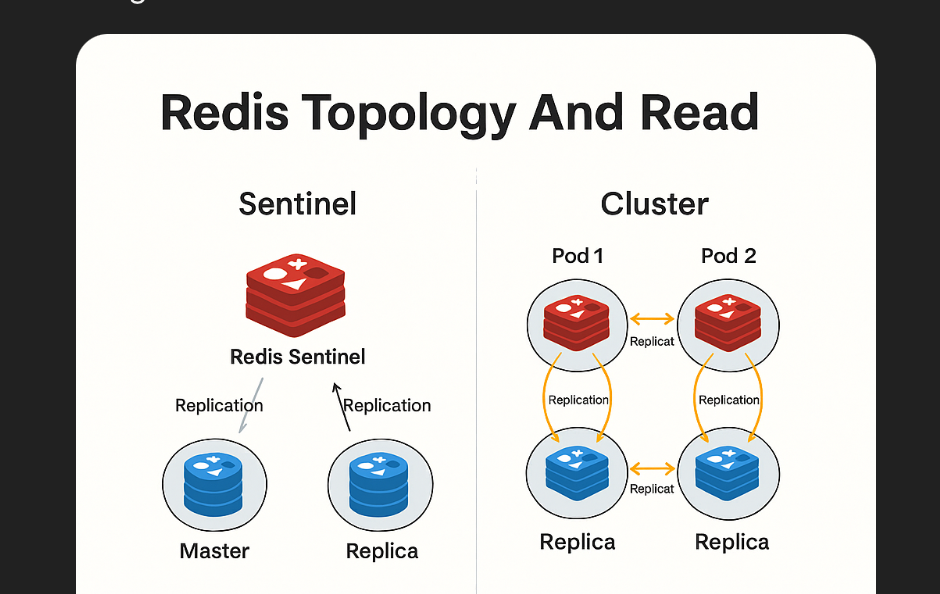
1. Redis Topology 개요
| 형태 | ��설명 |
|---|---|
| Standalone | 단일 인스턴스 운영 |
| Master-Slave | 읽기 전용 Slave로 Read Scale-out 지원 |
| Sentinel | 마스터 장애 시 자동 Failover 지원 |
| Cluster | 샤딩 기반 분산 처리 + 자동 Failover 지원 |
2. 클라이언트별 Topology 변경 대응 전략
✅ Lettuce
- Adaptive Refresh:
enableAllAdaptiveRefreshTriggers() - 주기적 Refresh:
enablePeriodicRefresh(Duration.ofSeconds(10)) - Topology 변경에 빠르게 대응 가능
🍃 Lettuce 설정 예시 (Kotlin/Java)
val topologyRefreshOptions = ClusterTopologyRefreshOptions.builder()
.enableAllAdaptiveRefreshTriggers()
.enablePeriodicRefresh(Duration.ofSeconds(10))
.build()
val clusterClientOptions = ClusterClientOptions.builder()
.topologyRefreshOptions(topologyRefreshOptions)
.build()
val redisClusterClient = RedisClusterClient.create(redisURIs)
redisClusterClient.setOptions(clusterClientOptions)
✅ Redisson
- scanInterval: topology 스캔 주기 (권장: 5~10초)
- 자동 장애 복구 / slot 변경 반영 가능
🍷 Redisson 설정 예시 (YAML 기반)
clusterServersConfig:
scanInterval: 5000
failedSlaveReconnectionInterval: 3000
retryAttempts: 3
retryInterval: 1500
🔁 클라이언트별 Topology 변경 (Failover) 대응 정리
| 클라이언트 | Sentinel 환경 대응 | Cluster 환경 대응 |
|---|---|---|
| Lettuce | ✅ 자동 재연결, 마스터 변경 감지 Topology refresh 필요 없음 | ✅ MOVED 응답 기반 자동 topology refresh Adaptive + Periodic 설정 시 빠른 대응 |
| Redisson | ✅ 마스터 변경 자동 감지 scanInterval 내에서 반영됨 | ✅ 주기적인 slot 스캔으로 반영 slot-to-node 매핑 변경 시 대응 가능 |
- Sentinel 환경에서는 클라이언트가 마스터 변경을 자동 감지하여 reconnect
- Cluster 환경에서는 MOVED 응답 또는 주기적 refresh로 slot 이동에 대응
3. MOVED 응답 발생 조건 및 처리
- 클라이언트가 key에 대한 슬롯(slot)은 정확하게 계산하지만,
- 클러스터의 slot-to-node 매핑이 변경된 경우,
- 클라이언트가 이 변경을 반영하지 못하면
MOVED응답 발생
MOVED 12345 192.168.0.10:6379
→ 클라이언트는 topology refresh 수행 후 재시도
4. Redis Rebalancing (슬롯 재분배)
- Redis는 자동으로 rebalancing 하지 않음
- 수동 명령으로만 ��가능:
redis-cli --cluster reshard또는rebalance - 운영자가 명시적으로 수행한 경우에만 MOVED 발생 가능성 있음
5. Read 전략 - ReadFrom
Lettuce / Redisson 공통 지원
| 전략 | 설명 |
|---|---|
| MASTER | 항상 master에서 읽음 (최신 보장) |
| REPLICA | 항상 slave에서 읽음 (성능 우선, 최신 보장 안 됨) |
| REPLICA_PREFERRED | slave 우선, 없으면 master fallback |
| NEAREST | latency 기준으로 가장 가까운 노드 선택 |
✅ 실무 추천
MASTER: 정합성 필수 (결제, 상태, 인증 등)REPLICA_PREFERRED: 캐시, 상품조회 등 read-heavy 서비스
✅ 주의
- Redis replication은 비동기, 즉 slave는 최신 데이터를 반영하지 못할 수 있음
- write 직후 read 시 stale data 발생 가능성 있음
📘 Lettuce의 ReadFrom 설정 예시
val connection = redisClusterClient.connect()
connection.setReadFrom(ReadFrom.REPLICA_PREFERRED)
📘 Redisson의 ReadFrom 설정 예시
Redisson은 내부적으로 master/slave 구분 후 자동 처리하며, 수동 설정은 일반적으로 필요 없음. 다만 읽기 전략은 config 기반으로 적용 가능.
6. CircuitBreaker 적용 시 유의점
- Redis는 매우 빠르므로 일반적으로 CircuitBreaker 적용 대상이 아님
- 적용 시:
- failureRateThreshold 높게 설정 (예: 70%)
- read timeout, fallback 경로에만 적용 고려
- Redis 실패보다는 fallback(DB/API) 요청에 Breaker 적용 권장
7. 결론 요약
| 목적 | 전략 |
|---|---|
| 데이터 정합성 필요 | ReadFrom.MASTER |
| 성능 / 캐시 목적 | ReadFrom.REPLICA_PREFERRED |
| topology 대응 | Lettuce: adaptive refresh + periodic refresh Redisson: scanInterval 설정 |
| MOVED ��대응 | 클라이언트 설정 + 리샤딩 작업 시점 통제 |
| rebalancing 시점 제어 | redis-cli 명령 수동 실행 |
Redis Cluster 운영에서 중요한 것은 "클러스터 구조를 바꾸는 주체는 사람"이라는 점입니다. 클라이언트는 이를 빠르게 감지하고 대응할 수 있도록 설정만 잘 해주면, MOVED나 stale read 문제는 대부분 제어 가능합니다.