Airflow에서의 heavy data 처리에 대한 단게적 개선
· 8 min read

BackEnd Software Developer
외부 데이터 소스로부터 가져온 raw-data들에 대해 중복 데이터 제거 및 데이터 셋간의 관계 설정 및 데이터 클랜징 처리등의 것들을 하면서 대용량 데이터의 처리에 대해 단계적으로 개선한 내용을 간략히 정리하여 공유 합니다. 본 글의 내용은 성능 병목을 개선하기 위한 단계별 전략을 일반적인 케이스로 정리한 가이드입니다. 각 단계는 실제로 성능 향상에 효과적인 접근법을 순차적으로 나열한 것입니다.
1단계: 기본 ORM 기반 배치 Upsert
- ORM을 사용해 한 번에 여러 개의 레코드를 upsert 처리
- 예시: SQLAlchemy + PostgreSQL
ON CONFLICT - 문제점:
- 대량의 데이터를 처리할 경우 SQL 파라미터 개수 제한 초과 (
32767) - ORM overhead로 인한 느린 처리 속도
- 대량의 데이터를 처리할 경우 SQL 파라미터 개수 제한 초과 (
Samples
# imports
import io
import logging
import re
from sqlalchemy.dialects.postgresql import insert as pg_insert
from sqlalchemy.engine import Result
from sqlalchemy.ext.asyncio import AsyncSession
from sqlalchemy.orm import class_mapper
from sqlalchemy.sql import Executable
from typing import List, Union
@dataclass
class NormalizedHeavyRecord:
...
async def upsert_many(self, records: List[DrugDocumentParagraphRecord]) -> int:
if not records:
return 0
total_upserted = 0
batch_size = 50 # first need to try with small size, and then increase it as you check working fine.
for i in range(0, len(records), batch_size):
batch = records[i:i + batch_size]
stmt = self._build_upsert_stmt(batch)
result = await self._execute_statement(stmt)
total_upserted += self._get_row_count(result)
return total_upserted
def _get_row_count(self, result: Result) -> int:
# return len(result.fetchall())
return len(result.scalars().all())
def _build_upsert_stmt(
self, records: Union[NormalizedHeavyRecord, List[NormalizedHeavyRecord]]
) -> Executable:
is_bulk = isinstance(records, list)
model = NormalizedHeavyRecord
# Extract all column keys except the primary key (`id`)
# content_hash is unique key for the data, so you need to build and save it with the data
mapper = class_mapper(model)
column_keys = [col.key for col in mapper.columns if col.key not in ("id", "content_hash")]
insert_stmt = pg_insert(model)
if is_bulk:
values = [vars(record) for record in records]
else:
values = vars(records)
# Remove _sa_instance_state (added by SQLAlchemy ORM)
if is_bulk:
for v in values:
v.pop("_sa_instance_state", None)
else:
values.pop("_sa_instance_state", None)
update_stmt = insert_stmt.on_conflict_do_update(
index_elements=["content_hash"],
set_={key: getattr(insert_stmt.excluded, key) for key in column_keys}
).returning(NormalizedHeavyRecord.id)
return update_stmt.values(values)
async def _execute_statement(self, stmt: Executable) -> Result:
result: Result = await self.session.execute(stmt)
await self.session.commit()
return result
2단계: 소규모 Batch 처리 도입
- 전체 데이터를 일정 크기(batch_size)로 나눠 반복 처리
- 예시:
batch_size = 500 ~ 1000
- 장점:
- 트랜잭션 부담 감소
- 파라미터 제한 회피
- 한계:
- 성능 개선 효과는 제한적
3단계: 병렬 async worker 처리
- asyncio 기반의 병렬 실행 도입
asyncio.Semaphore(n)을 사용해 동시에 n개의 트랜잭션을 동시 처리- 장점:
- I/O가 많은 작업에 적합
- 주의:
- 세션 분리 필요
- 트랜잭션 단위 rollback은 개별로만 가능
Samples
async def persist_doc_paragraphs():
records = all_data
semaphore = asyncio.Semaphore(5)
batch_size = 300
async def worker(batch):
async with semaphore:
async with factory() as session:
repository = NormalizedHeavyRecordRepository(session)
return await repository.upsert_many(batch)
tasks = [worker(records[i:i + batch_size]) for i in range(0, len(records), batch_size)]
results = await asyncio.gather(*tasks)
return sum(results)
4단계: COPY + 임시 테이블 + ON CONFLICT UPDATE
COPY로 임시 테이블에 입력 후 INSERT INTO target SELECT ... FROM tmp ON CONFLICT(...) DO UPDATE
- 도입 시점:
- 레코드 수가 수천~수백만건 이상인 경우
- 주요 이슈:
- 문자열 필드의 탭, 개행 문자 제거 필요
- 타입 일치(예: TEXT → INT 캐스팅 주의)
- 장점:
- 수십배 이상 빠른 성능
- 기존 데이터 upsert를 안전하게 수행
- COPY와 upsert를 조합해 가장 강력한 성능 확보
- 예시 흐름:
- 임시 테이블 생성 (ON COMMIT DROP)
- COPY INTO 임시 테이블
- INSERT INTO 실제 테이블 + ON CONFLICT
Samples
async def upsert_many_by_copy(
self,
records: List[NormalizedHeavyRecord],
batch_size: int = 10000
) -> int:
if not records:
return 0
total_upserted = 0
for i in range(0, len(records), batch_size):
batch = records[i:i + batch_size]
count = await self._copy_upsert_batch(batch)
total_upserted += count
return total_upserted
async def _copy_upsert_batch(self, batch: List[DrugDocumentParagraphRecord]) -> int:
# 필드 순서 중요: COPY에 사용될 컬럼 순서
# better specifing all columns but not primary key columns such as id
columns = []
# COPY ... FROM STDIN
conn = await self.session.connection()
raw_conn = await conn.get_raw_connection()
pg_conn = raw_conn.driver_connection # ← 핵심
# 임시 테이블로 COPY
async with pg_conn.transaction():
tmp_table_name = "tmp_sample_data"
target_table_name = "sample_data"
await self.create_tmp_table(columns, pg_conn, tmp_table_name)
await self.copy_data_to_tmp_table(batch, columns, pg_conn, tmp_table_name)
result = await self.insert_data_to_target_table(columns, pg_conn, target_table_name, tmp_table_name)
# 예: 'INSERT 0 5231' → row count 추출
count = int(result.split()[-1])
logger.info(f"[NormalizedHeavyRecord] COPY upserted {count} rows.")
return count
async def insert_data_to_target_table(self, columns, pg_conn, target_table_name, tmp_table_name):
# 타입 캐스팅이 필요한 컬럼 정의 format: column_name: TYPE(e.g. INTEGER)
type_casts = {}
# INSERT FROM tmp → 본 테이블로 ON CONFLICT UPSERT
select_clause = await self.build_select_clause(columns, type_casts)
update_clause = await self.build_update_clause(columns)
insert_sql = f"""
INSERT INTO {target_table_name} ({", ".join(columns)})
SELECT {select_clause} FROM {tmp_table_name}
ON CONFLICT (content_hash) DO UPDATE SET {update_clause};
"""
result = await pg_conn.execute(insert_sql)
return result
async def copy_data_to_tmp_table(self, batch, columns, pg_conn, tmp_table_name):
# CSV로 변환
# asyncpg requires source to be a bytes-like object (not str)
buffer = await self.build_csv_buffer(batch, columns) # COPY INTO 임시 테이블
await pg_conn.copy_to_table(
table_name=tmp_table_name,
source=buffer,
format="text",
columns=columns
)
async def create_tmp_table(self, columns, pg_conn, tmp_table_name):
await pg_conn.execute(f"""
CREATE TEMP TABLE {tmp_table_name} (
{', '.join(f"{col} TEXT" for col in columns)}
) ON COMMIT DROP;
""")
async def build_update_clause(self, columns):
# UPSERT 대상 컬럼 (content_hash는 제외)
update_clause = ", ".join(
f"{col} = EXCLUDED.{col}" for col in columns if col != "content_hash"
)
return update_clause
async def build_select_clause(self, columns, type_casts):
# SELECT 절에서 캐스팅 적용
select_clause = ", ".join(
f"CAST({col} AS {type_casts[col]})" if col in type_casts else col
for col in columns
)
return select_clause
async def build_csv_buffer(self, batch, columns):
buffer = io.StringIO()
for r in batch:
row = [
getattr(r, col) if getattr(r, col) is not None else r"\N"
for col in columns
]
buffer.write("\t".join(str(value) for value in row) + "\n")
buffer.seek(0)
return buffer
5단계: 전처리 필수! Sanitize 단계
- COPY의 경우 필드 개수 누락, 타입 불일치, 줄바꿈으로 인한 레코드 깨짐 등 에러 발생 가능성 높음
- Sanitize 처리 항목:
- None →
\N - 탭/줄바꿈/캐리지 리턴 제거
- strip 처리
- 타입 명확화 (str/int)
- None →
Samples
def _sanitize(self, value):
_value = value
if _value is None:
return r"\N"
if isinstance(_value, str):
# COPY-safe 처리: 탭/줄바꿈 제거
_value = (re.sub(r'[\r\n\t]+', ' ', _value)
.replace("\\", "\\\\")
.strip())
# noinspection PyUnboundLocalVariable
return str(_value)
async def build_csv_buffer(self, batch, columns):
buffer = io.BytesIO()
for idx, r in enumerate(batch):
row = [self._sanitize(getattr(r, col, None)) for col in columns]
if len(row) != len(columns):
logger.warning(f"[COPY] ❗ Row length mismatch at index={idx} → got {len(row)} fields")
logger.warning(f"[COPY] Row content: {row}")
continue # 또는 raise Exception(...)
# noinspection PyTypeChecker
buffer.write(("\t".join(row) + "\n").encode("utf-8"))
buffer.seek(0)
return buffer
6단계: 점진적 도입 및 병렬 COPY 확장
- 위 전략들을 조합하여 다음과 같이 구성:
- ① 소규모 batch 단위로 나눔
- ② 각 batch를 async로 병렬 전개
- ③ 각 batch 내에서는 COPY 사용
부록: 테스트 시 고려사항
- DB connection pool 크기 (동시 커넥션 수 초과 주의)
- Airflow/ETL 스케줄러의 리트라이 ��및 타임아웃 설정
- 데이터 정합성 확인 (예:
row count,hash 비교,diff 로그)
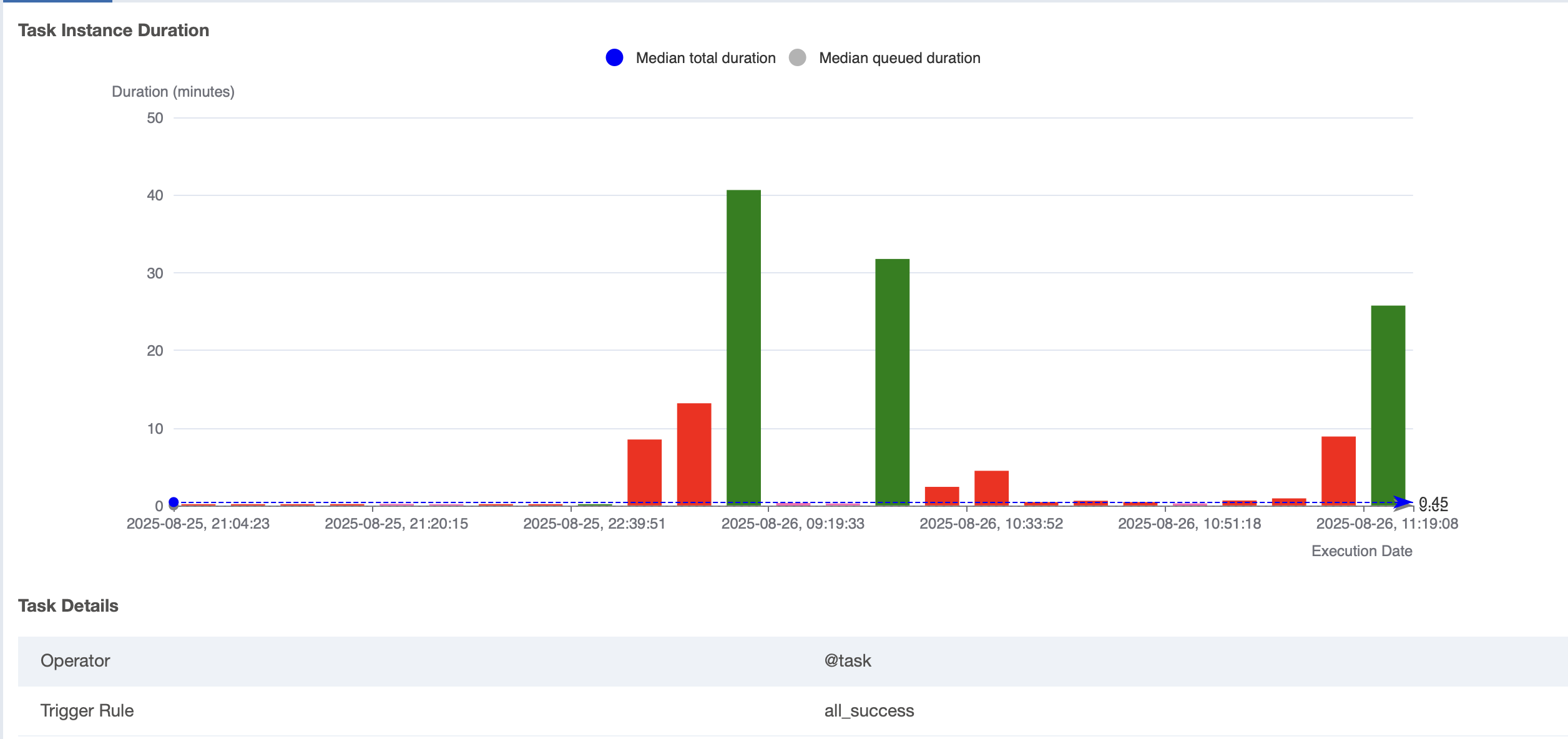
끝으로 저의 경우, 40분이 걸리던 작업을 25분으로 단축 했습니다. 아래의 그래프를 참고해주세요. :)